I recently built a water-cooled Raspberry Pi cluster and a lot of people asked how the cluster would compare to a computer because Raspberry Pi’s themselves aren’t seen as being particularly powerful.
If you haven’t already, have a look at my post on building the Pi Cluster.
How the cluster compares to a traditional computer isn’t really an easy question to answer. It depends on a number of factors and what metrics you measure it against. So this got me thinking of how to fairly compare the cluster to a computer in a way that doesn’t rely too heavily on the software being run and uses my Pi Cluster in the way it was intended when I built it,.

The cluster, and Raspberry Pi’s in general, aren’t designed for gaming or rendering high-end graphics, so obviously won’t perform well against a computer in this respect. But my intention behind building this cluster, apart from learning about and experimenting with cluster computing was to run mathematical models and simulations.
The Test Script
I initially thought of doing something along the lines of calculating Pi to a particular number of decimal places, but then I stumbled across a simple 4 node cluster setup mentioned in The Mag Pi which was used to find prime numbers up to a certain limit. This seemed like a good comparison as it is simple to understand and edit, it is easily adjustable and it can be run on Windows PCs, Macs and Raspberry Pi’s, so you can even join in and see how your computer compares.
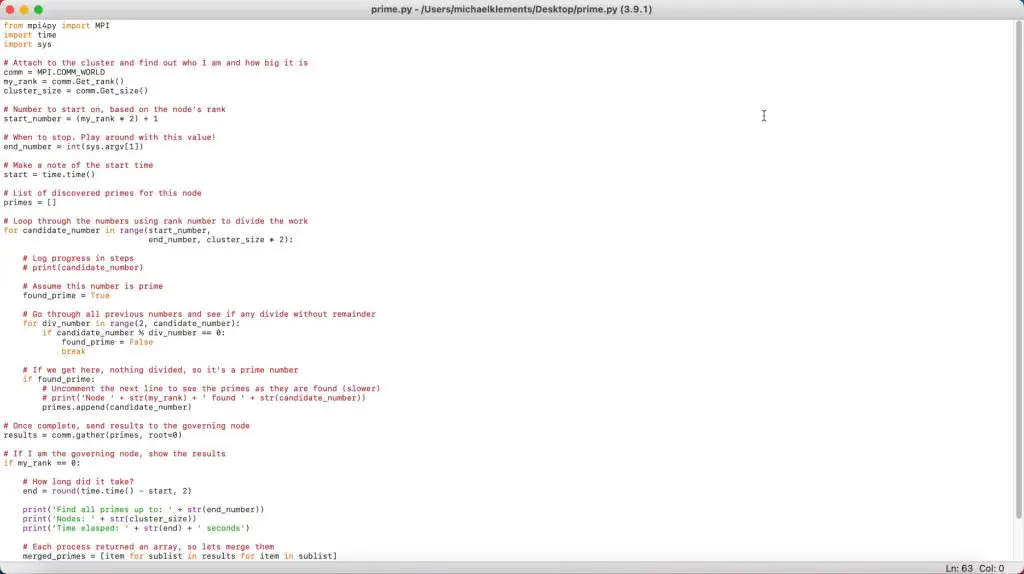
The script just runs through each number, up to a limit, and checks its divisibility to figure out if it is a prime number or not. I have simplified their cluster script so that it can be run on a PC, Mac or single Raspberry Pi.
import time
import sys
#Start and end numbers
start_number = 1
end_number = 10000
#Record the test start time
start = time.time()
#Create variable to store the prime numbers and a counter
primes = []
noPrimes = 0
#Loop through each number, then through the factors to identify prime numbers
for candidate_number in range(start_number, end_number, 1):
found_prime = True
for div_number in range(2, candidate_number):
if candidate_number % div_number == 0:
found_prime = False
break
if found_prime:
primes.append(candidate_number)
noPrimes += 1
#Once all numbers have been searched, stop the timer
end = round(time.time() - start, 2)
#Display the results, uncomment the last to list the prime numbers found
print('Find all primes up to: ' + str(end_number))
print('Time elasped: ' + str(end) + ' seconds')
print('Number of primes found ' + str(noPrimes))
#print(primes)I know that this is a very inefficient way of searching for prime numbers, but the intention is to make the script computationally expensive so that the processors have to work. There are some interesting thoughts and algorithms for finding prime numbers if you’d like to do some further reading.
For each setup, we’ll be testing the time it takes to find all prime numbers up to 10,000, 100,000 and 200,000.
I’ll be doing 5 comparisons, running the simulation on two laptops – a 2020 MacBook Air and a somewhat outdated HP Laptop running Windows 10 Pro. We’ll then compare these laptops to a single Pi 4B running at 1.5Ghz, then overclock the single Pi to 2.0Ghz, and then finally run the simulation on the Raspberry Pi Cluster with all of the Pis overclocked to 2.0Ghz.
There were a few requests on my build video to compare the cluster to a one of AMDs Ryzen CPU’s. So if any of you are running one, please try running the Python script which you can download above and share the results in the comments section. I’d also be interested to see how the Pi 400 performs if anyone has one of those.
Edit – Multi-process Test Script
Thanks to Adi Sieker for putting together a multi-process version of the script. This script makes use of all available cores and threads on the computer it’s being run on, so should give much better comparative results for multi-core processors.
I’ll add my updated test results for each system running this script at the end of this post.
import multiprocessing as mp
import time
#max number to look up to
max_number = 10000
#four processes per cpu
num_processes = mp.cpu_count() * 4
def chunks(seq, chunks):
size = len(seq)
start = 0
for i in range(1, chunks + 1):
stop = i * size // chunks
yield seq[start:stop]
start = stop
def calc_primes(numbers):
num_primes = 0
primes = []
#Loop through each number, then through the factors to identify prime numbers
for candidate_number in numbers:
found_prime = True
for div_number in range(2, candidate_number):
if candidate_number % div_number == 0:
found_prime = False
break
if found_prime:
primes.append(candidate_number)
num_primes += 1
return num_primes
def main():
#Record the test start time
start = time.time()
pool = mp.Pool(num_processes)
#0 and 1 are not primes
parts = chunks(range(2, max_number, 1), 1)
#run the calculation
results = pool.map(calc_primes, parts)
total_primes = sum(results)
pool.close()
#Once all numbers have been searched, stop the timer
end = round(time.time() - start, 2)
#Display the results, uncomment the last to list the prime numbers found
print('Find all primes up to: ' + str(max_number) + ' using ' + str(num_processes) + ' processes.')
print('Time elasped: ' + str(end) + ' seconds')
print('Number of primes found ' + str(total_primes))
if __name__ == "__main__":
main()Testing The Laptops And Individual Pi
Now that we know what we’re going to be doing, let’s get started with testing the computers.
I’ll start off on my Windows PC. The windows PC has a 7th generation dual-core i5 processor running at 2.5GHz.

Let’s start off by running the script to 10,000.
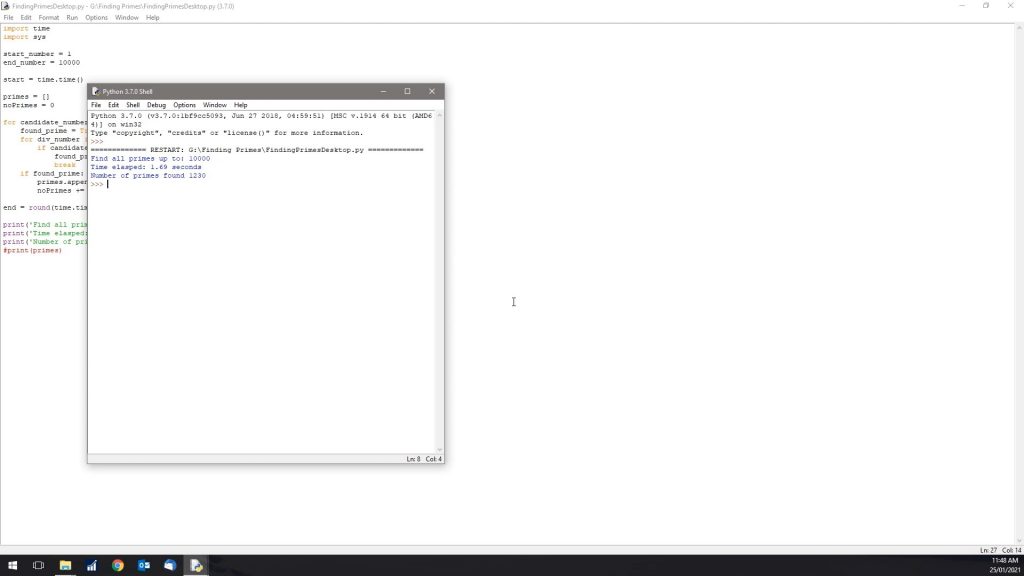
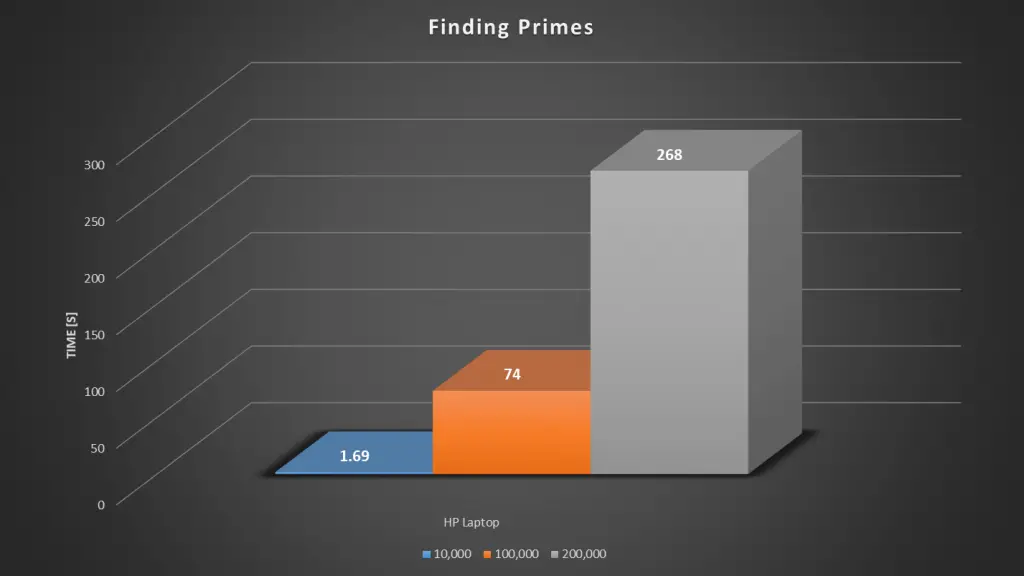
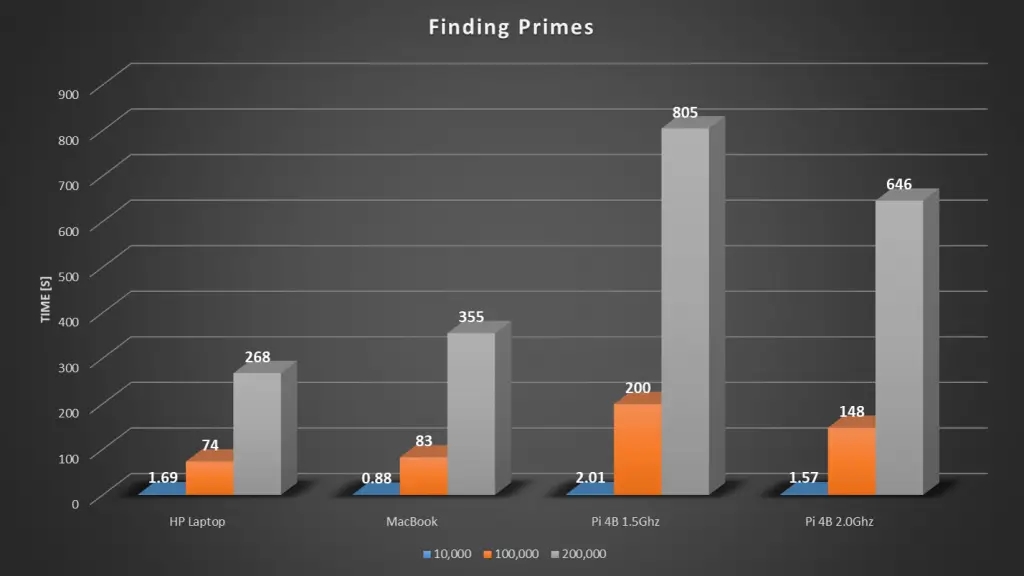
So as expected, that was completed pretty quickly, 1.69 seconds to find 1230 prime numbers below 10,000.
Now let’s try 100,000. Remember that even though 100,000 is only ten times more than 10,000, it’s going to take significantly longer than 10 times the time, because there are exponentially more factors to check as the numbers get larger.
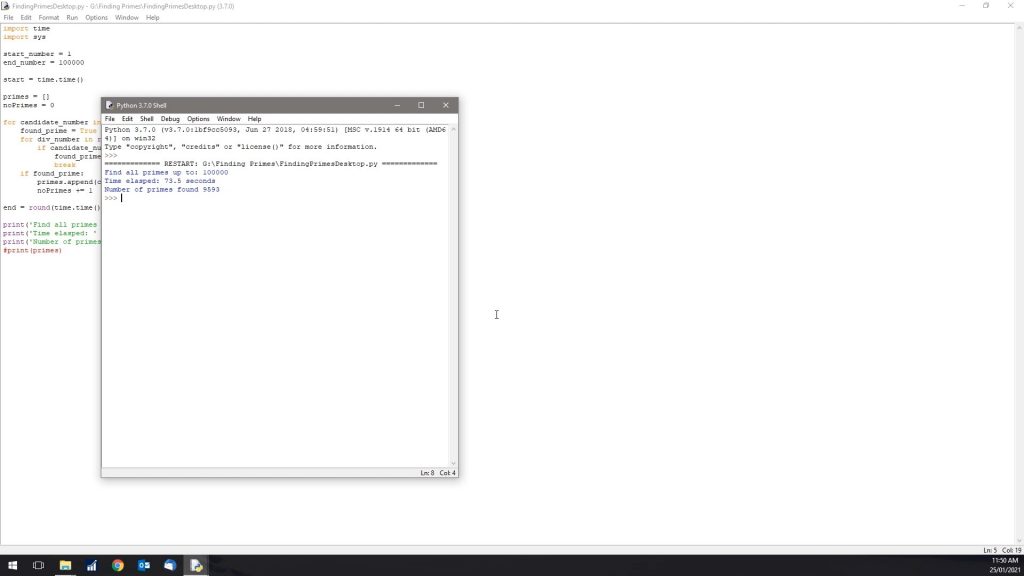
So running the test to 100,000, we get a time of 73 seconds, which is a minute and 13 seconds and we found 9593 prime numbers.
Lastly, lets try 200,000.
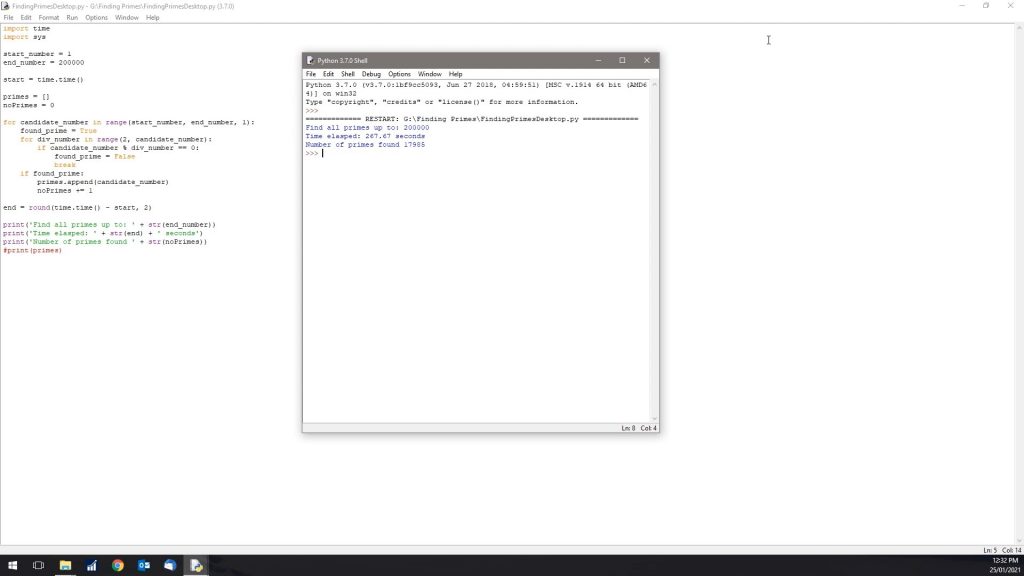
So it took 267 seconds or a little under 5 minutes to find the prime numbers to 200,00 and we found 17,985 primes.
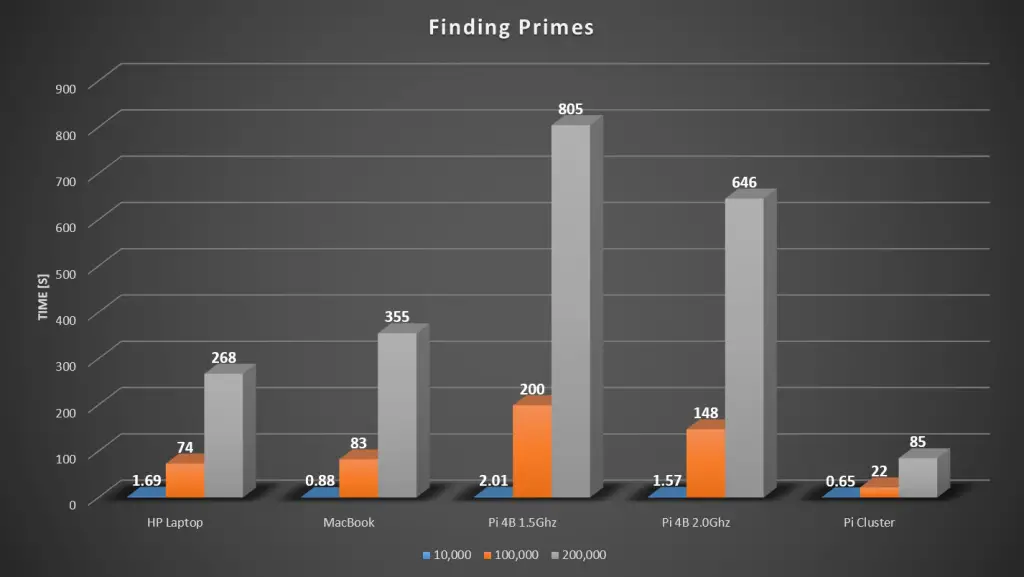
Here’s a summary of the HP laptop’s results.
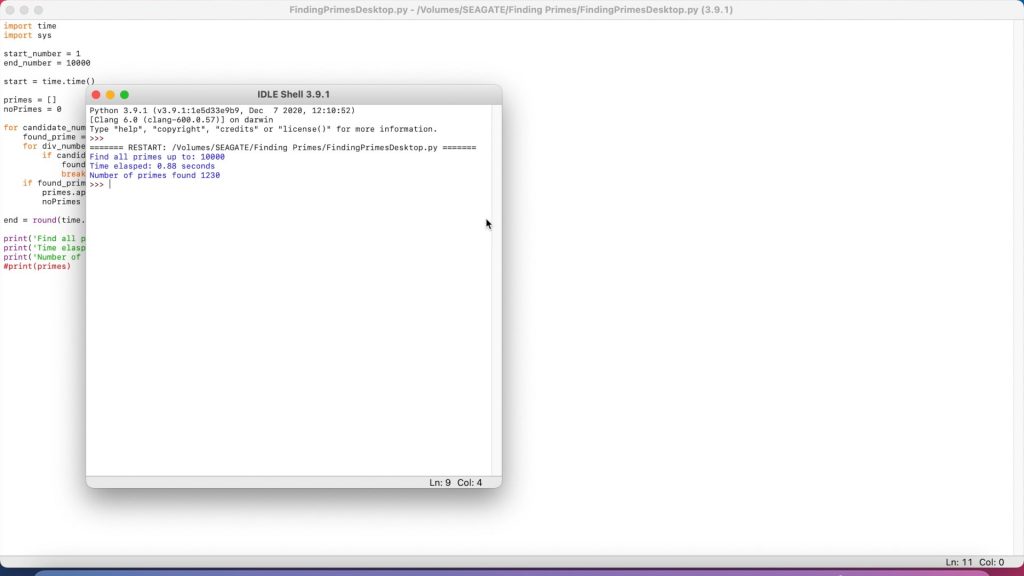
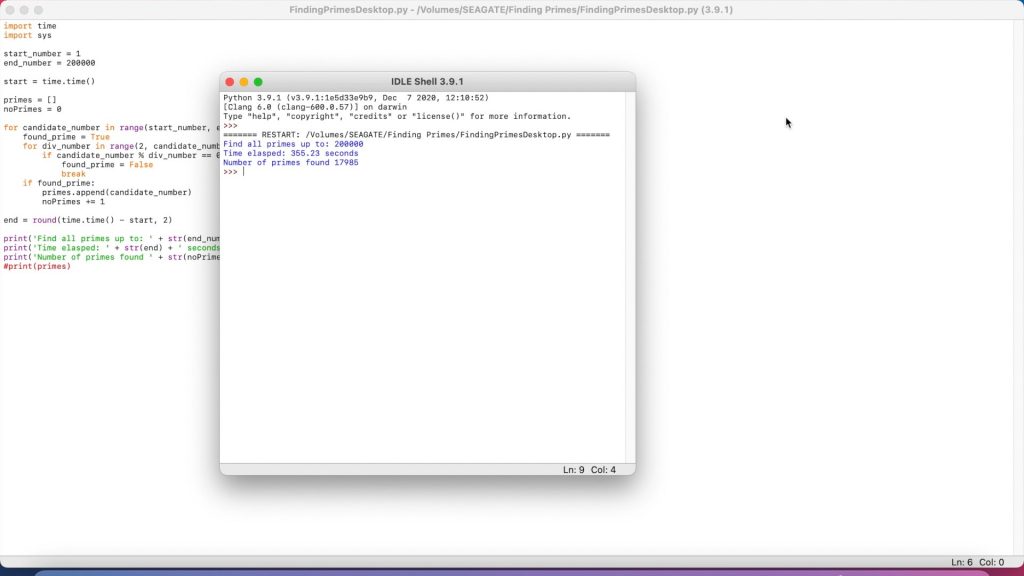
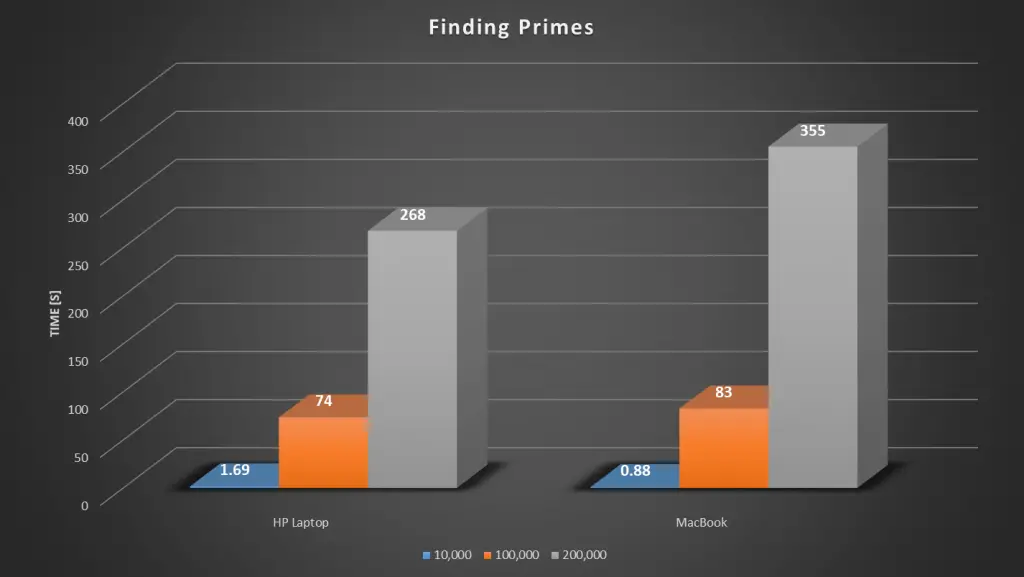
Next, we’ll look at the MacBook Air. The MacBook Air has a 1.6 GHz Dual Core i5 processor, let see how that compares to the older HP laptop. We’d expect the MacBook to be a bit slower than the PC as it’s CPU is only running at 1.6GHz, while the PC is running at 2.5Ghz.

The MacBook Air was quicker to 10,000 but then took a little longer than the PC for the next two tests, taking just under 6 minutes to find the primes up to 200,000.
Here’s a summary of the results of the two tests so far:
Let’s now move on to the singe Raspberry Pi running at 1.5Ghz.

The Pi 4B has a quad-core ARM Coretex-A72 processor.
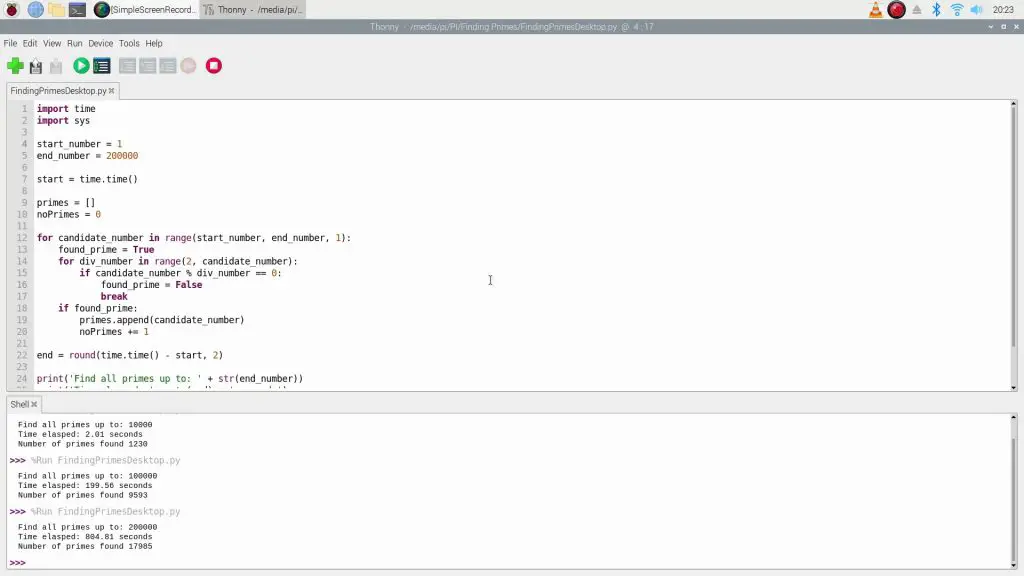
Even to 10,000, we can already see that the Pi is quite a bit slower than the other computers, taking 2 seconds for the first 10,000 and taking a little over 13 minutes to get to 200,000.
Next we’ll overclock the Pi to 2.0Ghz and see what sort of difference we see.
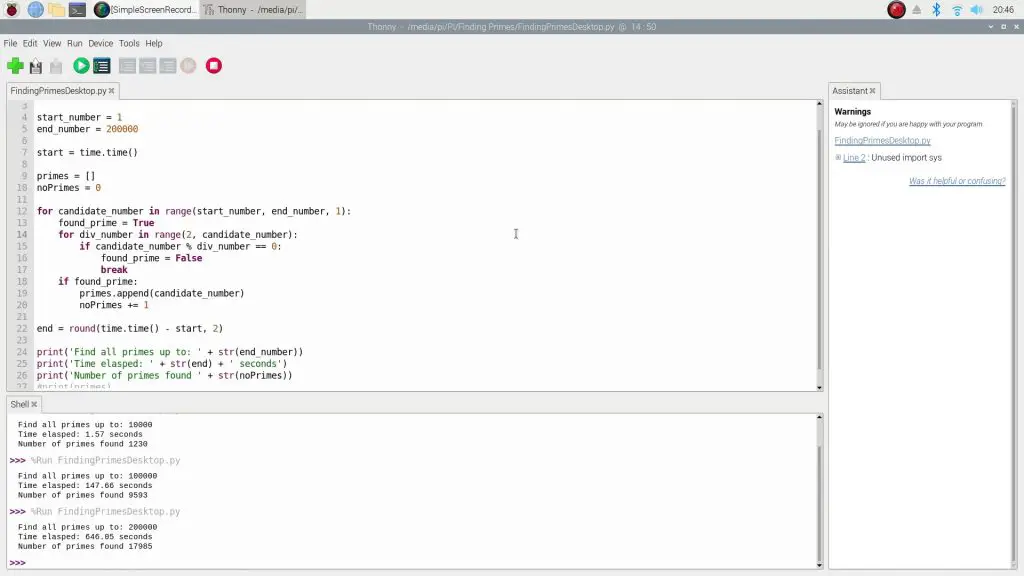
Overclocking the Pi has made a bit of an improvement. It took 1.57 seconds to 10,000, and around 11 minutes to get to 200,000.
Here’s a summary of the results of our tests of the individual computers:
Setting Up The Raspberry Pi Cluster
Next, we need to get the Pi’s all overclocked and working together in a cluster. To do this, there are a couple of things we need to set up.

I’ve installed a fresh copy of Raspberry Pi OS on the host or master node and then a copy of Raspberry Pi OS Lite on the other 7 nodes.
Prepare Each Node For SSH
Boot them up and then run the following lines to update them:
sudo apt -y update
sudo apt -y upgradeNext, run;
sudo raspi-configAnd change each Pi’s password, hostname. I used hostnames Node1, Node2 etc.. Also, make sure that SSH is turned on for each Pi so that you can access them over the network.
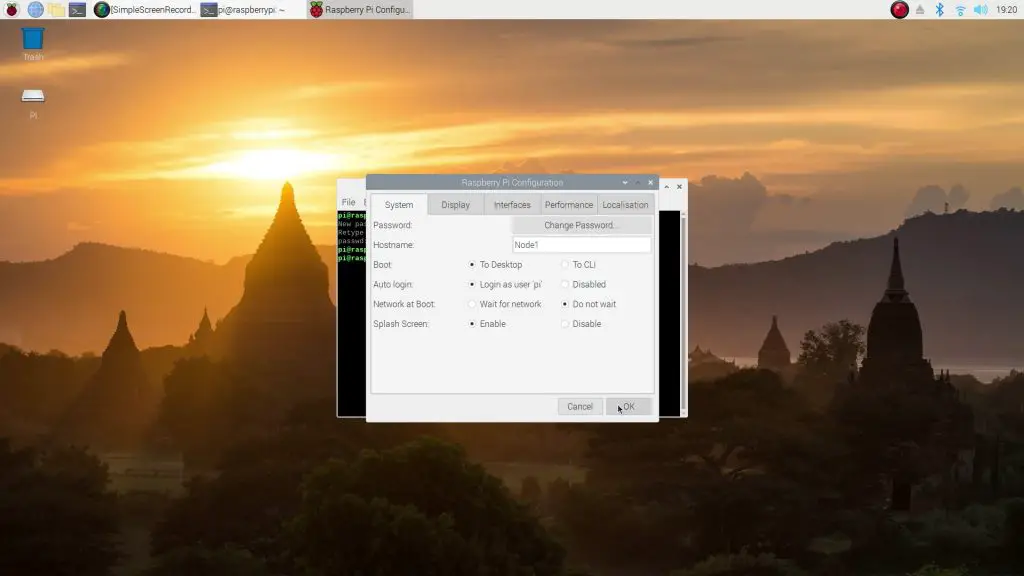
Next, you need to assign static IP addresses to your Pi’s. Make sure that you’re working in a range which is not already assigned by your router if you’re not working on a dedicated network.
sudo nano /etc/dhcpcd.confThen add the following lines to the end of the file:
interface eth0
static ip_address=192.168.0.1/24I used IP addresses 192.168.0.1, 192.168.0.2, 192.168.0.3 etc.
Then reboot your Pi’s and you should then be able to do the rest of the setup through Node 1.
We can now use the NMAP utility to see that all 8 nodes are online:
nmap 192.168.0.1-8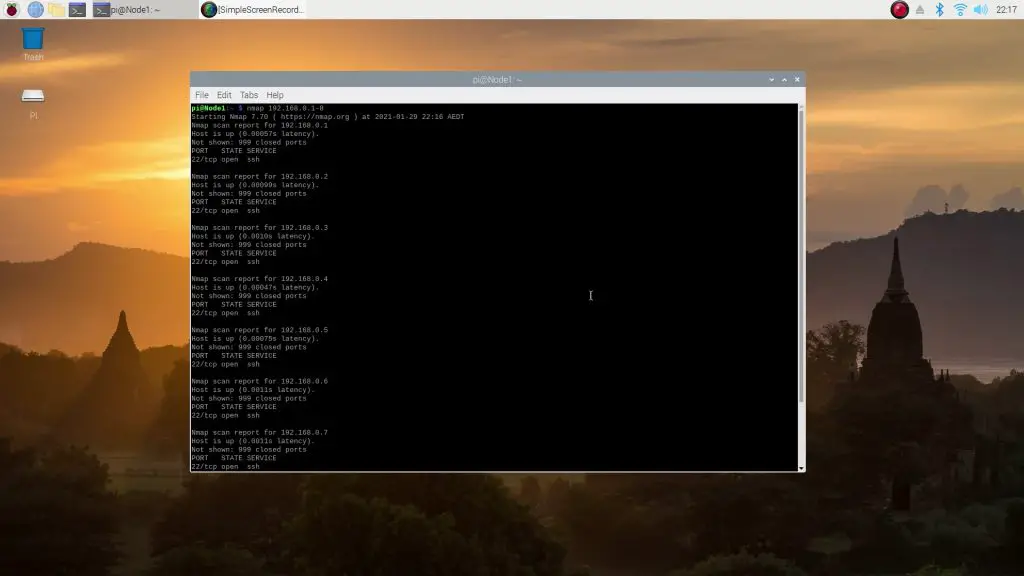
Overclock Each Node To 2.0 GHz
Next, we need to overclock each Pi to 2.0 GHz. I’ll do this from node 1 and SSH into each node to overclock it.
SSH into each Pi by entering into the terminal on Node1:
ssh pi@192.168.0.2You’ll then be asked to enter your username and password for that node and you can then edit the config file by entering:
sudo nano /boot/config.txtFind the line which says #uncomment to overclock the arm and then add/edit the following lines:
over_voltage=6
arm_freq=2000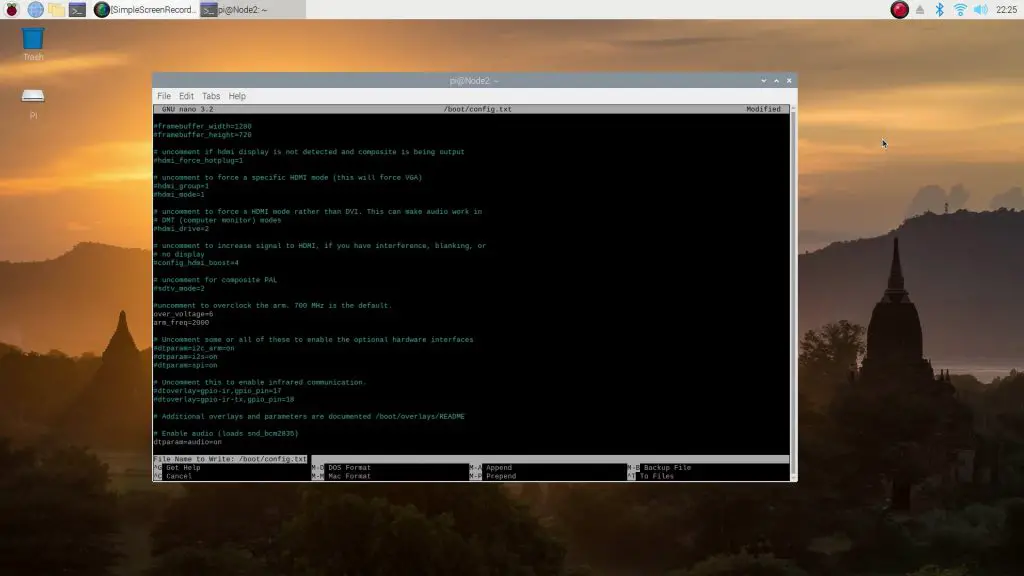
Reboot each node once you’ve edited and saved the file.
Create SSH Key Pairs So That You Don’t Need To Use Passwords
Next, we need to allow the Pis to communicate with the host without requiring a password. We do this by creating SSH keys for the host and each of the nodes and sharing the keys between them.
Let’s start by creating the key on the host by entering:
ssh-keygen -t rsa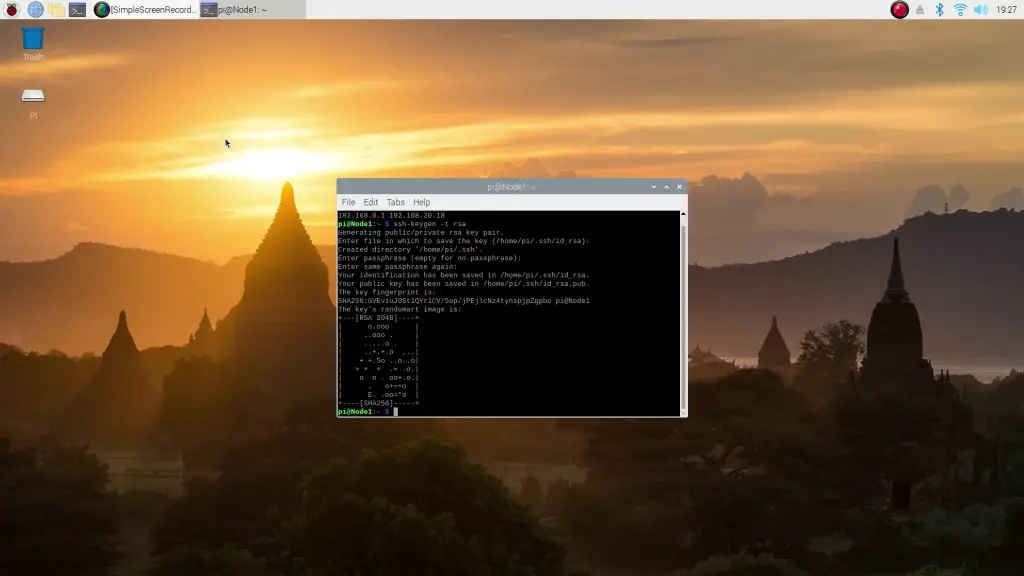
Just hit ENTER or RETURN for each question, don’t change anything or create a passphrase.
Next, SSH into each node as done previously and enter the same line to create a key on each of the nodes:
ssh-keygen -t rsa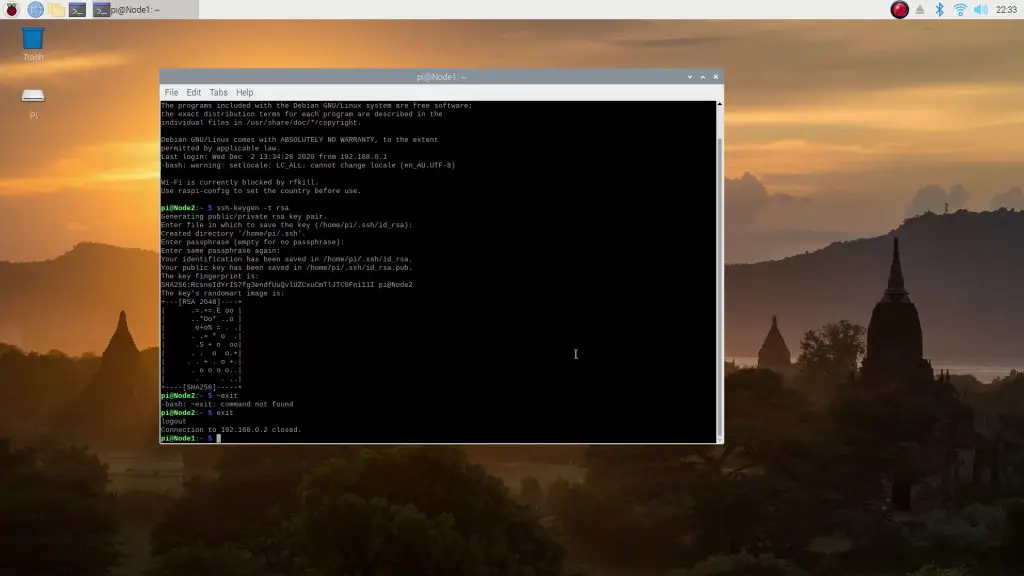
Before you exit or disconnect from each node, copy the key which you’ve created to the master node, node 1:
ssh-copy-id 192.168.0.1Finally, do the same on the master node, copying it’s key to each of the other nodes:
ssh-copy-id 192.168.0.2You’ll obviously need to increment the last digit of the IP address and repeat this for each of your nodes so that the key is copied to all nodes.
This is only done in pairs between the host and each node, so the nodes aren’t able to communicate with each other, only with the host.
You should now be able to SSH into each Pi from node 1 without requiring a password.
ssh '192.168.0.2'Install MPI (Message Passing Interface) On All Nodes In The Raspberry Pi Cluster
Next, we’re going to install MPI, which stands for Message Passing Interface, onto all of our nodes. This allows the Pis to delegate tasks amongst themselves and report the results back to the host.
Let’s start by installing MPI on the host node by entering:
sudo apt install mpich python3-mpi4py
Again use SSH to then install MPI onto each of the other nodes using the same script:
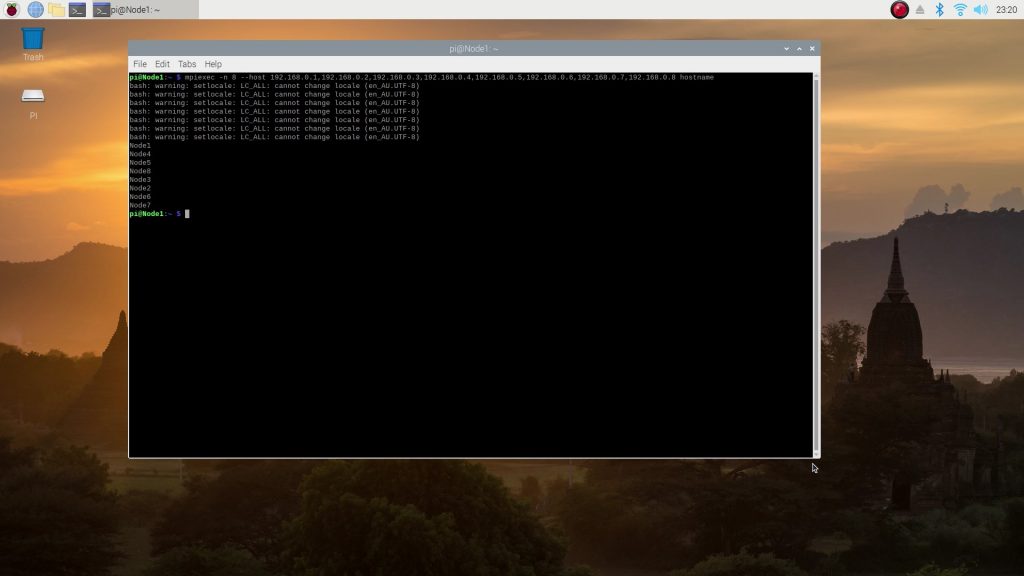
Once you’ve done this on all of your nodes, you can test that they’re all working and that MPI is running by trying the following:
mpiexec -n 8 --host 192.168.0.1,192.168.0.2,192.168.0.3,192.168.0.4,192.168.0.5,192.168.0.6,192.168.0.7,192.168.0.8 hostnameYou should get a report back from each node with it’s hostname:
Copy The Prime Calculation Script To Each Node
The last thing to do is to copy the Python script to each of the Pis, so that they all know what they’re going to be doing.
Here is the script we’re going to be running on the cluster:
The easiest way to do this is with the following line:
scp ~/prime.py 192.168.0.2:You’ll again obviously need to increment the IP address for each node, and the above assumes that the script prime.py is in the home directory.
You can check that this has worked by opening up an SSH connection on any node and trying:
mpiexec -n 1 python3 prime.py 1000Once this is working, then we’re ready to try out our cluster test.
Testing The Raspberry Pi Cluster
We’ll start out with calculating the primes up to 10,000. So we’ll start a cluster operation with 8 nodes, list the node’s IP addresses and then tell the operation what script to run, in which application to run it and finally the limit to run the test up to:
mpiexec -n 8 --host 192.168.0.1,192.168.0.2,192.168.0.3,192.168.0.4,192.168.0.5,192.168.0.6,192.168.0.7,192.168.0.8 python3 prime.py 10000The cluster was able to get through the first 10,000 in 0.65 seconds – faster than either of our computers. Which is quite surprising given that the system needs to manage communication to and from the nodes as well.
Here are the results for the test to 10,000, 100,000 and then to 200,000:
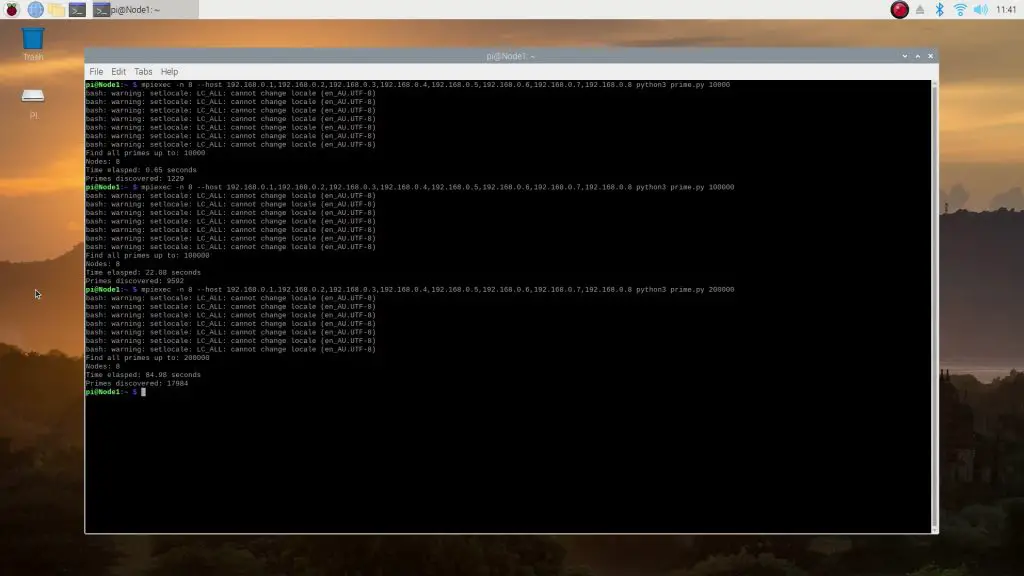
The search to 200,000 took just 85 seconds, which is again a little over 3 times faster than the Windows PC and 4 times faster than the MacBook. It was also a just a little slower than 8 times faster than the individual Pi.
Here is a comparison of the combined results from all of the tests done:
Lastly, I just ran the simulation to 500,000 on the cluster to see how fast it would be.
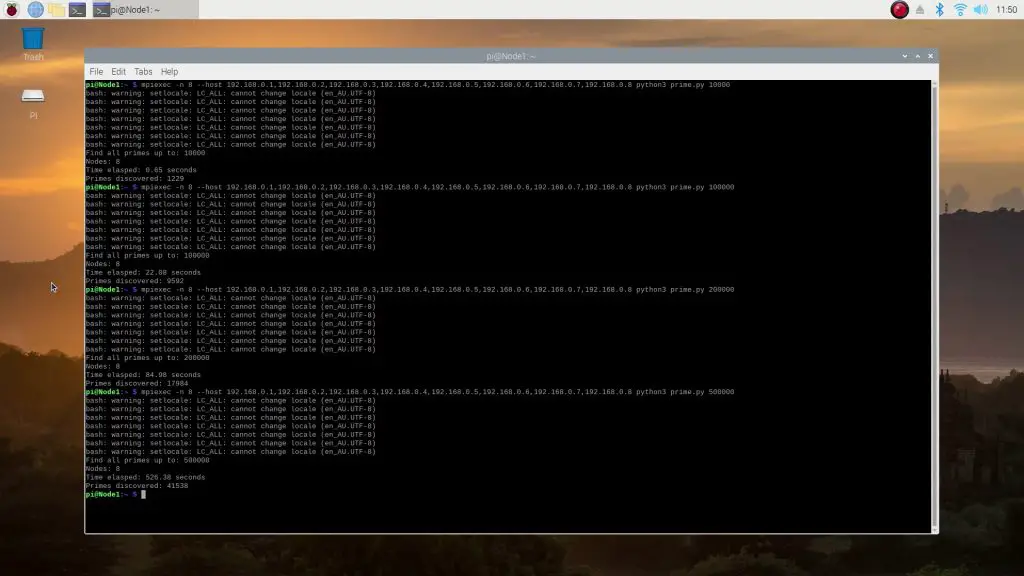
That took 526 seconds, or a little under 9 minutes.
I plotted a trend and forecast the 500,000 times for the other tests so that you can see how they compare. I’ve converted all of these values to minutes to make them a bit more understandable.
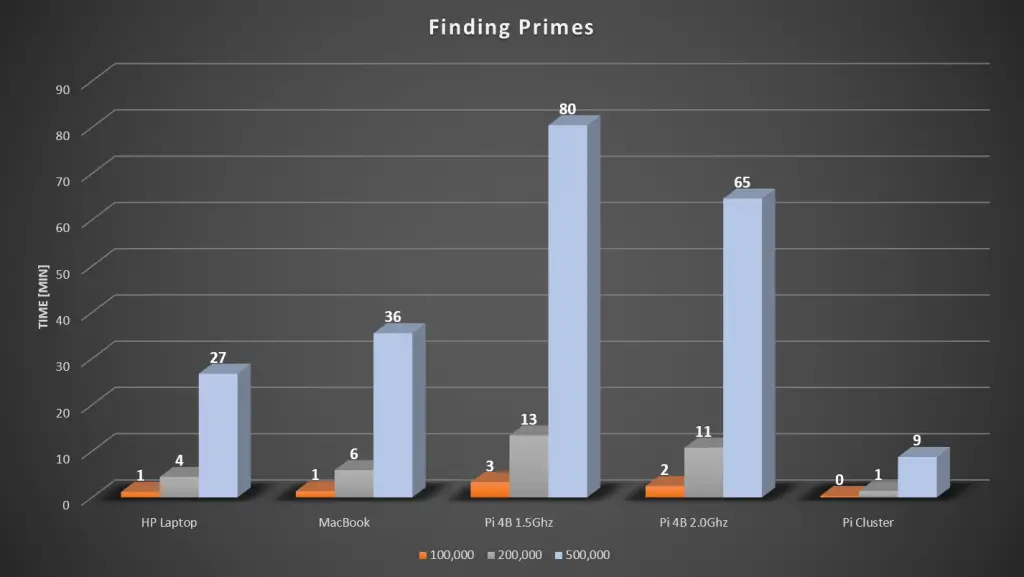
So our cluster was able to beat the PC and Mac quite significantly, which might be somewhat surprising, but that is the power of cluster computing. You can imagine that when running really large simulations, which often take a couple of days on a PC, being able to run the simulation just 2-3 times faster is a massive saving. A week-long simulation on the PC can be completed by the Pi Cluster in just two and a half days.
Now obviously we could cluster PCs as well to achieve better simulation times, but remember that each Pi node in this setup costs just $35, so you can build a pretty powerful computer for a few hundred dollars using Raspberry Pis. You’re also not limited to just 8 nodes, you could add another 8 nodes to this setup for around $400 and you’d have a cluster which performs 6 times faster than the PC.
Multi-Process Test Results
As mentioned in an earlier edit in the post, Adi Sieker put together a multi-process version of the script.
Here are the results of the tests done so far (I’ll keep adding to them as I complete them on each platform):
HP Laptop – Using 16 processes:
- 10,000 – 0.9 s
- 100,000 – 18.27 s
- 200,000 – 66.99 s
- 500,000 – 374.3 s (6 mins 15 s)
What About The Temperature Of The Loop?
I also checked the temperature of the master node, which is midway through the cooling loop (5th in the loop), to see how warm it was after the test:
It was only around 8 degrees above room temperature after the test.
Next, I’m going to be doing a full thermal test on the Raspberry Pi Cluster to check how it performs under full load for a duration of time. So be sure to check back in a week or two or subscribe to my channel for updates on Youtube.
As mentioned earlier, feel free to download the script and try it out on your own computer and share your results with us in the comments section. We’d love to see how some other setups compare.
Came to notice your water cooled PI cluster in YT.
Since you have shown bench marks, I tried to run your scripts on my machine too Ryzen 1700 in windows 10.
The timing was close to what you have shown; For 100K 42sec for the single process script and 24sec for the multi process script.
Then I noticed that even with multi process script running only one thread on the task manager is at full load, the others are close to idle. I see a number of python process running. But the processor utilization is 0 on those (except for the one). So in effect the script is not utilizing the full power of the processors.
Not sure if the story is different in Linux
I tried the prime calculation of 100K (similar to your code) in C++/C#, both gives sub second performance (with full cpu utilization).
I tested on ubuntu on 2 different machines. one has 2 cores, one has 6. Same thing. The multiprocessor script doesn’t utilize all the cores. To me this means this test is not accurate.
There is probably a better script / program out there that can be run to take advantage of SMP.
This is probably due to the Python Global Interpreter Lock that prevents more than one thread in a python process from running at a time. See https://en.wikipedia.org/wiki/Global_interpreter_lock. One way to circumvent this is to run multiple processes on the same machine.
That makes complete sense. Reading that I saw mention of HammerDB that is written in or utilizes TCL (not sure exactly what I know about TCL) so maybe worth playing around with that.
Saw the same Python Script effect on my HP-Pavilion NP192AA-ABA p6140f x64-based PC Processor Intel(R) Core(TM)2 Quad CPU Q8200 @ 2.33GHz, 2333 Mhz, 4 Core(s), 4 Logical Processor(s).
Reviewed the Python Script “FindingPrimesMulti.py” in the “FindingPrimesMulti-1.zip” file. Needed to change the following script code
” parts = chunks(range(2, max_number, 1), 1) ”
to
” parts = chunks(range(2, max_number, 1), num_processes) ”
to correct the failing to assign ranges of numbers to each processes.
Adding the Benchmark Results: (see notes below)
Find all primes up to: 10000 using 4 processes.
Time elasped: 0.61 seconds
Number of primes found 1229
Find all primes up to: 100000 using 16 processes.
Time elasped: 14.61 seconds
Number of primes found 9592
Find all primes up to: 200000 using 16 processes.
Time elasped: 51.24 seconds
Number of primes found 17984
Find all primes up to: 500000 using 16 processes.
Time elasped: 297.43 seconds
Number of primes found 41538
Notes:
1) Used “FindingPrimesMulti.py” with Python Script code change “parts = chunks(range(2, max_number, 1), num_processes)” to correct the failure to assign ranges of numbers to each processes.
2) OS: Microsoft Windows 10 Pro, Version 10.0.18363 Build 18363
3) Hardware: HP-Pavilion p6140f x64 Intel Core2 Quad CPU Q8200 @ 2.33GHz, 2333 Mhz, 4 Core(s), 4 Logical Processor(s), Memory (RAM) 8.00 GB
4) Finding: Tested using 4 to 16 processes found that by using more processes like 16 kept all 4 cores more active because some assigned ranges ended quicker then others.
Lacking Raspberry Cluster hardware for kicks created a Virtual Raspberry Cluster.
OS/Hardware used: Windows 10 Pro 64-bit 8GB RAM, Intel Core(TM)2 Quad CPU Q8200 @2.33GHz, 2333Mhz, 4 Core(s), SSD Drive
Installed Oracle VM VirtualBox 6.0.24 64-bit. https://download.virtualbox.org/virtualbox/6.0.24/ (VirtualBox-6.0.24-139119-Win.exe)
Because VT-x is not available on my Intel Core2 Quad CPU had to use Raspberry Pi Desktop 4.29 32-bit ISO (2021-01-11-raspios-buster-i386.iso)
Created VirtualBox “Raspberry Pi Desktop 4.29”
VM Debian (32-bit), 1 CPU (32-bit max), Enable PAE/NX, RAM 1GB, PIIX3, PS/2 Mouse, VBoxSVGA 128MB, Hardware Clock in UTC time
SATA Port0-cd “2021-01-11-raspios-buster-i386.iso”, Port1-Raspberry.vdi 32GB dyn,
Net Adpt1-Intel 1000MTDesktop Bridged adpt Realtek PCIe GbE Family Controller
Net Adpt2-Intel 1000MTdesktop NAT
Shared Folders: Path: c:\users\”user”\Desktop\Share, FolderName: Share, MountPoint: /home/pi/share
Virtual booting of VirtualBox “Raspberry Pi Desktop 4.29” is very i/o write sensitive to disk drive delays, avoided boot hangups by using a SSD Drive.
Updated VirtualBox “Raspberry Pi Desktop 4.29” VirtualBox Guest Additions 5.2.0 to 6.0.24 (cdrom: VBoxGuestAdditions_6.0.24.iso)
sudo sh /../../media/cdrom/VBoxLinuxAdditions.run
Used Router DHCP Reservation to assign permanent IP address to the four virtual cluster Nodes
Lacking a DSN Server updated all four virtual cluster nodes /etc/hosts adding “192.168.2.3_ node_” _=1,2,3,4
Cloned VirtualBox “Raspberry Pi Desktop 4.29” three times renaming them and their hostname to node_ _=1,2,3,4
Used Node1 as the Cluster Master node and followed your documented steps to complete the ssh & mpiexec cluster nodes setup.
Test VM Cluster setup:
mpiexec -n 4 –host node1,node2,node3,node4 hostname
node1
node3
node2
node4
Run VM Cluster Primes timings:
mpiexec -n 4 –host node1,node2,node3,node4 python3 /home/pi/share/prime.py 10000 >> ./share/VMPrimes.txt
Find all primes up to: 10000
Nodes: 4
Time elasped: 0.68 seconds
Primes discovered: 1229
mpiexec -n 4 –host node1,node2,node3,node4 python3 /home/pi/share/prime.py 100000 >> ./share/VMPrimes.txt
Find all primes up to: 100000
Nodes: 4
Time elasped: 79.38 seconds
Primes discovered: 9592
mpiexec -n 4 –host node1,node2,node3,node4 python3 /home/pi/share/prime.py 200000 >> ./share/VMPrimes.txt
Find all primes up to: 200000
Nodes: 4
Time elasped: 334.12 seconds
Primes discovered: 17984
mpiexec -n 4 –host node1,node2,node3,node4 python3 /home/pi/share/prime.py 500000 >> ./share/VMPrimes.txt
Find all primes up to: 500000
Nodes: 4
Time elasped: 2435.46 seconds
Primes discovered: 41538
Hi, I came here via your youtube video while browsing for things to do with my PI 400
I am old school basic, cobol and pascal, as i have had a PI3b for 2 years i have never used python or anything newer than excel macros 🙂
So i grabed python 3.94 from python.org to suit win 10 64 bit
this machine is my daily driver and internet machine and is a simple Lenovo thinkcentre core2 machine G3220 but it does have 12G ram
i only ran3 tests as it is late at night and i need to get some sleep
single core
10,000 0.59 seconds
100,000 50.95 seconds
Multi Core
100,000 29.85 seconds
On the weekend i will add python to my I3 6th gen laptop and the spare I7 4th gen used as a games machine by my son
Cheers
George
Thanks for sharing your results George. It would be interesting to try out on your older Pi3b as well if that’s still running.
I google and found no solution. I assume the work just can’t be split.
Because, this script here, that calculates a Monte Carlo Prime, does spawn the correct amount of -actually working- processes:
#!/usr/bin/python
import random
from multiprocessing import Pool, cpu_count
from math import sqrt
from timeit import default_timer as timer
def pi_part(n):
print(n)
count = 0
for i in range(int(n)):
x, y = random.random(), random.random()
r = sqrt(pow(x, 2) + pow(y, 2))
if r < 1:
count += 1
return count
def main():
start = timer()
np = cpu_count()
print(f'You have {np} cores')
n = 100_000_000
part_count = [n/np for i in range(np)]
with Pool(processes=np) as pool:
count = pool.map(pi_part, part_count)
pi_est = sum(count) / (n * 1.0) * 4
end = timer()
print(f'elapsed time: {end – start}')
print(f'π estimate: {pi_est}')
if __name__=='__main__':
main()
——-
There was a spam detection because I used a VPN. The comment didn't show up so I made the same one without VPN. However it says it's a duplicate and the other comment is not visible, so here I am writing something to change the comment to make it be visible. …
Can you post this to a pastebin somewhere? I’m cleaning it up but not sure i have indentation correct, it was all lost in your post.
I actually shared code here that you can run on multiprocessor systems, but the Moderator didn’t approve of it. Probably because this site ignores normal “new lines”, so it was all squeezed together.
It was calculating Monte Carlo primes. I think you can find it easily with Google. Python, of course.
Kind regards 🙂
Oh wait it worked! Huh…
Why pastebin? Is it impossible to copy it?
I googled looking for it but couldn’t find multi threaded version of it.
I tried this out on my AMD Ryzen 5900X, with the multi-cpu version of the script.
It’s quite amusing fun:
Find all primes up to: 200000 using 96 processes.
Time elasped: 60.58 seconds
Number of primes found 17984
Process finished with exit code 0
Thanks for sharing your results!
why has your 12 Core Processor needed more time for a less range. Im using an R7 3700x on 4,4 Ghz allcore on Win 10 with visual Studio Code.
Find all primes up to: 500000 using 64 processes.
Time elasped: 50.26 seconds
Number of primes found 41538
This Spam Protection is really annoying.
I changed the script to use all cores… You can find it as Comment of “MadMe86” on your YoutubeVideo
Results of my 3950X
First Script:
Find all primes up to: 200000
Time elasped: 90.6 seconds
Number of primes found 17985
MultiThread Script:
Find all primes up to: 200000 using 128 processes.
Time elasped: 54.47 seconds
Number of primes found 17984
with my modified Script:
Find all primes up to: 200000 using 32 processes.
Time elasped: 4.14 seconds
Number of primes found 17984
Find all primes up to: 1000000 using 32 processes.
Time elasped: 95.78 seconds
Number of primes found 78498
I am not a python expert so please forgive the quick and dirty code 😉
import multiprocessing as mp
import time
max_number = 10000
num_processes = mp.cpu_count()
def getchunks():
superList = []
for e in range(0, num_processes, 1):
subList = []
superList.append(subList)
i = 0
for i in range(2, max_number, 1):
superList[i % num_processes].append(i)
return superList
def calc_primes(numbers, arr):
num_primes = 0
primes = []
firstno = numbers[0] % num_processes
#Loop through each number, then through the factors to identify prime numbers
for candidate_number in numbers:
found_prime = True
for div_number in range(2, candidate_number):
if candidate_number % div_number == 0:
found_prime = False
break
if found_prime:
primes.append(candidate_number)
num_primes += 1
#print(num_primes)
arr[firstno] = num_primes
def main():
#Record the test start time
start = time.time()
resultList = mp.Array(‘i’,range(num_processes))
parts = getchunks()
processes = []
for i in parts:
p = mp.Process(target=calc_primes, args=(i, resultList))
processes.append(p)
p.start()
for process in processes:
process.join()
total_primes = sum(resultList)
end = round(time.time() – start, 2)
print(‘Find all primes up to: ‘ + str(max_number) + ‘ using ‘ + str(num_processes) + ‘ processes.’)
print(‘Time elasped: ‘ + str(end) + ‘ seconds’)
print(‘Number of primes found ‘ + str(total_primes))
if _name_ == “__main__”:
main()
when I ran the multi-CPU version on my AMD Ryzen 9 3900X 12-Core Processor I got this
Find all primes up to: 100000 using 12 processes.
Time elasped: 14.98 seconds
Number of primes found 9592
that is not what I was expecting that’s way too slow. come to find out it’s only running on 1 thread/core.
I made a script that uses all available cores.
https://github.com/Kodi4444/CPU_benchmark.git
Hi Michael,
Thanks for posting this series. Finally got my 4x cluster up and running. Just to add to the mess of comments talking about single-core performance, I modified your prime.py script (The one using mpi4py) so it would utilize all cores of the Raspberry Pi 4. It uses the same algorithm that your code uses, or at least it’s close. With my 4x Nodes using 4x cores each (16 cores), I have close to twice the performance of your cluster! Just thought I would share my results.
https://github.com/joshjerred/mpi4py-with-multiprocessing-Check-for-primes
4x Raspberry Pi 4s running between 1.8 and 2.0 GHz
100,000 @ 9.68 seconds
200,000 @ 45.2 seconds
Hi Joshua,
Thanks for sharing your results and revised code! They’re quite impressive!
I just ran the script on my new Apple M1 MacBook Air with 8gb of RAM…here are my results
10,000 @ 0.44 seconds
100,000 @ 40.57 seconds
200,000 @ 160.66 seconds
I ran the multi-process version of the script on Apple M1 MacBook Air with 16 gb of RAM:
Find all primes up to: 10000 using 32 processes.
Time elasped: 0.81 seconds
Number of primes found 1229
Find all primes up to: 100000 using 32 processes.
Time elasped: 15.36 seconds
Number of primes found 9592
Find all primes up to: 200000 using 32 processes.
Time elasped: 57.22 seconds
Number of primes found 17984
You might want to correct the multiprocessing implementation.
Also, for the work defined by the algorithm used, distributing the load by simply splitting the search linearly is not efficient, quite often there are execution nodes/cores that end up starving for work.
I’m the same person from YT that shared an implementation using joblib to make use of the other cores in a PC, I’ve extended (and fixed) the multiprocessing implementation shown here, both implementations (joblib and the modified multiprocessing one) are available at:
https://drive.google.com/drive/folders/1_VUNGTMIvpuy_7pAXjTvD0MCGfQaf2NM?usp=sharing
In the multiprocessing implementation I’ve also expose a bit why it is not very efficient to split the work as it was done in the original script.
Thanks for the advice and the work you’ve done on the code, this is really useful to work through.
Updated the shared folder with a simpler version that doesn’t evaluate the work done per execution node, as such there is not extra overhead and the results comparable with the rest of the scripts in this webpage.
I’m probably digging too much into this rabbit hole, and this would probably be some nice subject for a blog post about distributed algorithms, but here it is.
For a the modified work distribution in an old Intel® Core™ i5-4570 CPU @ 3.20GHz × 4, with Python 3.8.5 in Ubuntu 20.04.2 LTS I got the following results when requesting work for 4 tasks in a Pool of 4 workers:
size: 10000 time: 0.09s primes: 1229
size: 50000 time: 1.9s primes: 5133
size: 100000 time: 7.16s primes: 9592
size: 200000 time: 26.56s primes: 17984
size: 500000 time: 146.88s primes: 41538
size: 1000000 time: 557.53s primes: 78498
Using the work distribution used in the initial run the results are as follows:
size: 10000 time: 0.14s primes: 1229
size: 50000 time: 2.89s primes: 5133
size: 100000 time: 11.51 primes: 9592
size: 200000 time: 40.85s primes: 17984
size: 500000 time: 246.78 primes: 41538
size: 1000000 time: 946.5 primes: 78498
Looking at the results, without balancing the work between the nodes the code runs almost twice as slower. This means that at least one node spent half of the total time taken doing nothing!
I suspect this gets worse as you add more nodes… you can mitigate it by subdividing the work into more sub-tasks, but then you’ll start to get more overhead as you set up more tasks. I might make a comparison later to check how it scales with the number of available worker nodes.
While for the sake of simplicity I guess the prime algorithm used it is fine for comparing the performance, I feel since the prime algorithm has a few snags with the work distribution something more easily split would be better, then again you might not have such an easy time with an real-world algorithm you wish to run.
Added a PDF to the shared folder with the results of my analysis.
Might give some useful insights… and yes… I was bored…
Had to give it a shot 🙂
Macbook Pro 16″ (2,3 GHz 8-Core Intel Core i9) 16gb ram.
FindingPrimesMulti.py – with ‘parts = chunks(range(2, max_number, 1), num_processes)’ fix.
Find all primes up to: 200000 using 64 processes.
Time elasped: 14.9 seconds
Number of primes found 17984
Awesome, thanks for sharing your results!
Find all primes up to: 500000 using 32 processes.
Time elasped: 142.17 seconds
Number of primes found 41538
I7-7700, using the corrected multi-processor script.
Thanks for sharing your results!
AMD 5800X
Summary of the benchmarking:
| Method | Work size | Tasks | Time (s) | Primes
| basic | 10000 | 16 | 0.08 | 1229
| halved | 10000 | 32 | 0.02 | 1229
| heuristic | 10000 | 16 | 0.02 | 1229
| basic | 50000 | 16 | 0.52 | 5133
| halved | 50000 | 32 | 0.49 | 5133
| heuristic | 50000 | 16 | 0.41 | 5133
| basic | 100000 | 16 | 1.96 | 9592
| halved | 100000 | 32 | 1.74 | 9592
| heuristic | 100000 | 16 | 1.56 | 9592
| basic | 200000 | 16 | 7.24 | 17984
| halved | 200000 | 32 | 6.47 | 17984
| heuristic | 200000 | 16 | 5.9 | 17984
| basic | 500000 | 16 | 42.51 | 41538
| halved | 500000 | 32 | 37.92 | 41538
| heuristic | 500000 | 16 | 34.01 | 41538
| basic | 1000000 | 16 | 157.78 | 78498
| halved | 1000000 | 32 | 142.46 | 78498
| heuristic | 1000000 | 16 | 128.3 | 78498
On my Ryzen 3600 without OC I used 48 processes (4 per each thread) and a chunk size of 192. (Seems to be the sweet spot on my CPU. But this has to profiled for your CPU individually!)
I tried the corrected script (https://gist.github.com/Nike-Prallow/072eb7079fdfbff3b824411e64db1123; contains also profiling facility) and it took me:
10k : 0.07s
100k : 2.54s
200k : 9.42s
500k : 54.44s
On my M1 Mac Mini, using 32 processes (4 per core) and chunk sizes 64-256:
10k : 1.1
100k : 4.0
200k : 12.2
500k : 66.0
Hi,
Just tried your instructions for Raspberry Pi Cluster. I have total three raspi’s running. Seems like they are reporting the results not as clustered but as individually.
$ mpiexec -n 3 –host 192.168.1.60,192.168.1.61,192.168.1.62 python3 prime.py 10000
bash: warning: setlocale: LC_ALL: cannot change locale (ja_JP.UTF-8)
bash: warning: setlocale: LC_ALL: cannot change locale (ja_JP.UTF-8)
Find all primes up to: 10000
Nodes: 1
Time elasped: 1.96 seconds
Primes discovered: 1229
Find all primes up to: 10000
Nodes: 1
Time elasped: 1.96 seconds
Primes discovered: 1229
Find all primes up to: 10000
Nodes: 1
Time elasped: 1.97 seconds
Primes discovered: 1229
According to your blog post it should be reporting as combined results but seems mine is not. Do you have any clue what is going wrong? I’m a newbie for clustering raspberry pi’s and would like to know how to make these little machine act like a super computer.
Dearest Tetsu,
Fancy seeing you here 😉
I saw your results initially as well. It’s quite likely you are not running the latest script. Please see my repo here, where i have attempted to combine this comment thread with the scripts mentioned, and it runs on my raspberrypi 3B+ and 4 pi-zero cluster just fine.
di0
well apparently that repo link didn’t post?
(https://bitbucket.org/di0/cluster-calc-primes)
Ran both just for the hell of it, here are the results on a Ryzen 9 3900x at 3940 MHz with 64 Gb ram
= RESTART: C:\Users\sidew\Downloads\FindingPrimesMulti-1\FindingPrimesMulti.py =
ValueError: need at most 63 handles, got a sequence of length 98
Find all primes up to: 10000 using 96 processes.
Time elasped: 0.84 seconds
Number of primes found 1229
= RESTART: C:\Users\sidew\Downloads\FindingPrimesMulti-1\FindingPrimesMulti.py =
Find all primes up to: 100000 using 96 processes.
Time elasped: 17.77 seconds
Number of primes found 9592
= RESTART: C:\Users\sidew\Downloads\FindingPrimesMulti-1\FindingPrimesMulti.py =
Find all primes up to: 200000 using 96 processes.
Time elasped: 66.75 seconds
Number of primes found 17984
Python 3.10.4 (tags/v3.10.4:9d38120, Mar 23 2022, 23:13:41) [MSC v.1929 64 bit (AMD64)] on win32
Type “help”, “copyright”, “credits” or “license()” for more information.
= RESTART: C:\Users\sidew\Downloads\FindingPrimesDesktop\FindingPrimesDesktop.py
Find all primes up to: 10000
Time elasped: 0.45 seconds
Number of primes found 1230
= RESTART: C:\Users\sidew\Downloads\FindingPrimesDesktop\FindingPrimesDesktop.py
Find all primes up to: 100000
Time elasped: 35.53 seconds
Number of primes found 9593
= RESTART: C:\Users\sidew\Downloads\FindingPrimesDesktop\FindingPrimesDesktop.py
Find all primes up to: 200000
Time elasped: 132.43 seconds
Number of primes found 17985